- 数组与容器的区别
- java 容器都有哪些?
- Collection 和 Collections 有什么区别?
- List、Set、Map 之间的区别是什么?
- HashMap 和 Hashtable 有什么区别?
- 如何决定使用 HashMap 还是 TreeMap?
- 说一下 HashMap 的实现原理?
- new HashMap(20) 容量最终为多少
- 扩容为什么是 2 的倍数
- HashSet 的底层实现
- ConCurrentHashMap 怎么实现线程安全,JDK1.7与JDK1.8中ConcurrentHashMap的一些变化
- ConCurrentHashMap HashTable 一定线程安全嘛
- HashMap线程不安全的体现
- HashMap 参考面试题
- ArrayList 怎么扩容?
- ArrayList 和 LinkedList 的区别是什么?
- 如何实现数组和 List 之间的转换?
- ArrayList 和 Vector 的区别是什么?
- ArrayList 和 LinkedList 的区别?
- Array 和 ArrayList 有何区别?
- 在 Queue 中 poll()和 remove()有什么区别?
- 哪些集合类是线程安全的?
- 迭代器 Iterator 是什么?
- Java中Comparable与Comparator的区别
- Arrays.sort 底层的排序算法是什么?
- Arrays.sort()方法中有双轴快排为什么还要有归并排序
数组与容器的区别
Java 中常用的存储容器就是数组和容器,二者有以下区别:
- 存储大小是否固定
- 数组的长度固定;
- 容器的长度可变。
- 数据类型
- 数组可以存储基本数据类型,也可以存储引用数据类型;
- 容器只能存储引用数据类型,基本数据类型的变量要转换成对应的包装类才能放入容器类中。
java 容器都有哪些?
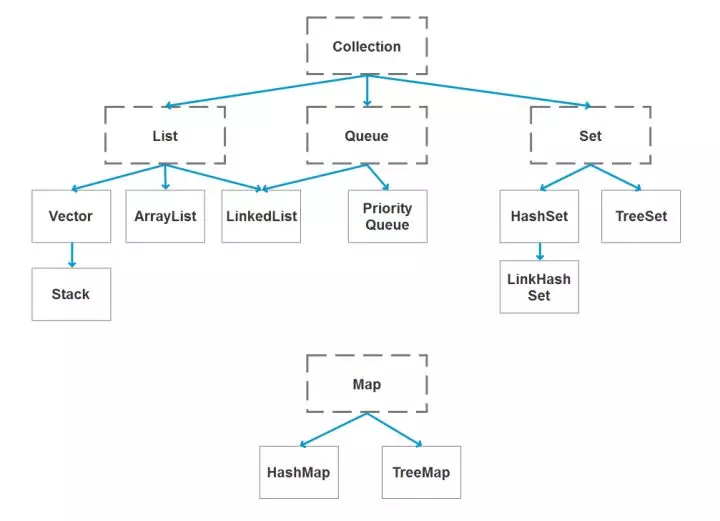
Collection 和 Collections 有什么区别?
- java.util.Collection 是一个集合接口(集合类的一个顶级接口)。它提供了对集合对象进行基本操作的通用接口方法。Collection接口在Java 类库中有很多具体的实现。Collection接口的意义是为各种具体的集合提供了最大化的统一操作方式,其直接继承接口有List与Set。
- Collections则是集合类的一个工具类/帮助类,其中提供了一系列静态方法,用于对集合中元素进行排序、搜索以及线程安全等各种操作。
List、Set、Map 之间的区别是什么?
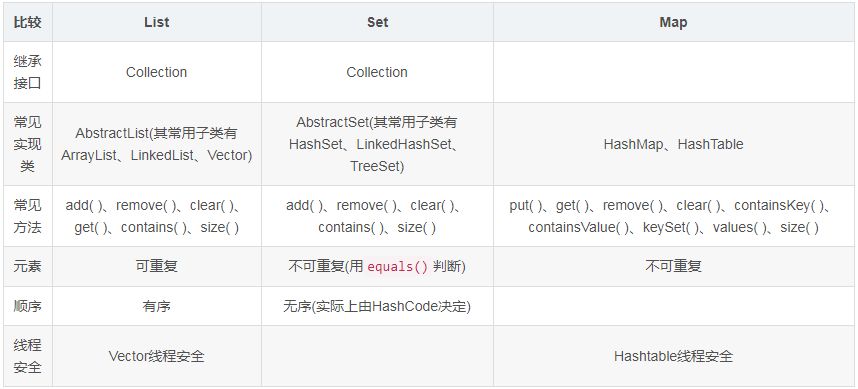
HashMap 和 Hashtable 有什么区别?
- hashMap 去掉了 HashTable 的contains方法,但是加上了containsValue() 和containsKey() 方法。
- hashTable 同步的,而 HashMap 是非同步的,效率上比 hashTable 要高。
- hashMap 允许空键值,而 HashTable 不允许。
如何决定使用 HashMap 还是 TreeMap?
对于在Map中插入、删除和定位元素这类操作,HashMap是最好的选择。然而,假如你需要对一个有序的key集合进行遍历,TreeMap是更好的选择。基于你的collection的大小,也许向HashMap中添加元素会更快,将map换为TreeMap进行有序key的遍历。
说一下 HashMap 的实现原理?
HashMap概述: HashMap是基于哈希表的Map接口的非同步实现。此实现提供所有可选的映射操作,并允许使用null值和null键。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
HashMap的数据结构:JDK8 之前底层实现是数组 + 链表,JDK8 改为数组 + 链表/红黑树,当链表长度大于8会转变成红黑树,红黑树元素小于6时会转变成链表。主要成员变量包括存储数据的 table 数组、元素数量 size、加载因子 loadFactor。
HashMap 中数据以键值对的形式存在,键对应的 hash 值用来计算数组下标,如果两个元素 key 的 hash 值一样,就会发生哈希冲突,被放到同一个链表上
table 数组记录 HashMap 的数据,每个下标对应一条链表,所有哈希冲突的数据都会被存放到同一条链表,Node/Entry 节点包含四个成员变量:key、value、next 指针和 hash 值。在JDK8后链表超过8会转化为红黑树
若当前数据/总数据容量>负载因子,Hashmap将执行扩容操作。默认初始化容量为 16,扩容容量必须是 2 的幂次方(方便 & 操作)、最大容量为 1« 30 、默认加载因子为 0.75
new HashMap(20) 容量最终为多少
初始化容量应该为 $20/负载因子 + 1$ 的最大的 2 的倍数,即 32
在后面 +1 是因为,扩容是在插入后,如果只有 6 个元素,插入第 6 个元素时索引会自增到 7,引发扩容
扩容为什么是 2 的倍数
-
加快哈希计算
减一后做与操作刚好截取hash值的低位。以16为例子,二进制是00….001111,做与操作截取的就是hash的低四位
-
减少哈希冲突
这是因为hashmap的hash值是hashCode右移16位得到的,这么做使得hash值的低位保留了高位的信息,所以只要低位就可以了。如果你不右移,那么高位信息是被浪费的,只利用低位信息,哈希碰撞的几率会大大增加
HashSet 的底层实现
HashSet底层原理完全就是包装了一下HashMapHashSet的唯一性保证是依赖与hashCode()和equals()两个方法,所以存入对象的时候一定要自己重写这两个方法来设置去重的规则。- 因为底层是
HashMap,而存储的又是key,所以没有get()方法来直接获取,只能遍历获取 - value 是PRESENT, PRESENT为HashSet类中定义的一个使用static final 修饰的常量,并无实际的意义
ConCurrentHashMap 怎么实现线程安全,JDK1.7与JDK1.8中ConcurrentHashMap的一些变化
ConCurrentHashMap HashTable 一定线程安全嘛
不一定,下面 step1 和 step2单独都是线程安全的,但一起使用,可能会导致线程不安全
public class CHMDemo {
public static void main(String[] args) throws InterruptedException {
ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap<String,Integer>();
map.put("key", 1);
ExecutorService executorService = Executors.newFixedThreadPool(100);
for (int i = 0; i < 1000; i++) {
executorService.execute(new Runnable() {
@Override
public void run() {
int key = map.get("key") + 1; //step 1
map.put("key", key);//step 2
}
});
}
Thread.sleep(3000); //模拟等待执行结束
System.out.println("------" + map.get("key") + "------");
executorService.shutdown();
}
}
解决方法,可以使用 synchronized 包裹 step1 和 step2
synchronized(this) {
// step1
// step2
}
HashMap线程不安全的体现
体现:
- JDK1.7 HashMap线程不安全体现在:死循环、数据丢失
- JDK1.8 HashMap线程不安全体现在:数据覆盖
改善:
- 数据丢失、死循环,JDK1.8 通过头插法改成尾插法解决
原因:
- JDK1.7 中,由于多线程对HashMap进行扩容,调用了HashMap#transfer(),具体原因:某个线程执行过程中,被挂起,其他线程已经完成数据迁移,等CPU资源释放后被挂起的线程重新执行之前的逻辑,数据已经被改变,造成死循环、数据丢失。
- JDK1.8 中,由于多线程对HashMap进行put操作,调用了HashMap#putVal(),具体原因:假设两个线程A、B都在进行put操作,并且hash函数计算出的插入下标是相同的,当线程A执行完第六行代码后由于时间片耗尽导致被挂起,而线程B得到时间片后在该下标处插入了元素,完成了正常的插入,然后线程A获得时间片,由于之前已经进行了hash碰撞的判断,所有此时不会再进行判断,而是直接进行插入,这就导致了线程B插入的数据被线程A覆盖了,从而线程不安全。
HashMap 参考面试题
ArrayList 怎么扩容?
在JDK1.8中,如果通过无参构造的话,初始数组容量为0,当真正对数组进行添加时(即添加第一个元素时),才真正分配容量,默认分配容量为10;当容量不足时(容量为size,添加第size+1个元素时),先判断按照1.5倍(位运算)的比例扩容能否满足最低容量要求,若能,则以1.5倍扩容,否则以最低容量要求进行扩容。
执行add(E e)方法时,先判断ArrayList当前容量是否满足size+1的容量; 在判断是否满足size+1的容量时,先判断ArrayList是否为空,若为空,则先初始化ArrayList初始容量为10,再判断初始容量是否满足最低容量要求;若不为空,则直接判断当前容量是否满足最低容量要求; 若满足最低容量要求,则直接添加;若不满足,则先扩容,再添加。
ArrayList 和 LinkedList 的区别是什么?
最明显的区别是 ArrrayList底层的数据结构是数组,支持随机访问,而 LinkedList 的底层数据结构是双向循环链表,不支持随机访问。使用下标访问一个元素,ArrayList 的时间复杂度是 O(1),而 LinkedList 是 O(n)。
如何实现数组和 List 之间的转换?
- List转换成为数组:调用ArrayList的toArray方法。
- 数组转换成为List:调用Arrays的asList方法。
ArrayList 和 Vector 的区别是什么?
- Vector是同步的,而ArrayList不是。然而,如果你寻求在迭代的时候对列表进行改变,你应该使用CopyOnWriteArrayList。
- ArrayList比Vector快,它因为有同步,不会过载。
- ArrayList更加通用,因为我们可以使用Collections工具类轻易地获取同步列表和只读列表。
ArrayList 和 LinkedList 的区别?
- ArrayList 基于数组,可 O(1) 访问;LinkedList 基于双向链表,只能遍历(由于是双向链表可以根据 index 选择从哪边开始遍历,时间有所缩减)
- ArrayList 空间浪费在需预留空间;LinkedList 空间花费在于存储了头尾指针
- ArrayList 基于哈希,每插一个元素可能会进行元素重排(数据量小时没多大差别);LinkedList 插入删除开销固定
Array 和 ArrayList 有何区别?
- Array可以容纳基本类型和对象,而ArrayList只能容纳对象。
- Array是指定大小的,而ArrayList大小是固定的。
- Array没有提供ArrayList那么多功能,比如addAll、removeAll和iterator等。
在 Queue 中 poll()和 remove()有什么区别?
poll() 和 remove() 都是从队列中取出一个元素,但是 poll() 在获取元素失败的时候会返回空,但是 remove() 失败的时候会抛出异常。
类比还有 add(E e), remove(), element() VS offer(E e), poll(), peek()
哪些集合类是线程安全的?
- vector:就比arraylist多了个同步化机制(线程安全),因为效率较低,现在已经不太建议使用。在web应用中,特别是前台页面,往往效率(页面响应速度)是优先考虑的。
- statck:堆栈类,先进后出。
- hashtable:就比hashmap多了个线程安全。
- enumeration:枚举,相当于迭代器。
迭代器 Iterator 是什么?
迭代器是一种设计模式,它是一个对象,它可以遍历并选择序列中的对象,而开发人员不需要了解该序列的底层结构。迭代器通常被称为“轻量级”对象,因为创建它的代价小。
Java中Comparable与Comparator的区别
相同
- Comparable和Comparator都是用来实现对象的比较、排序
- 要想对象比较、排序,都需要实现Comparable或Comparator接口
- Comparable和Comparator都是Java的接口
区别
- Comparator位于java.util包下,而Comparable位于java.lang包下
- Comparable接口的实现是在类的内部(如 String、Integer已经实现了Comparable接口,自己就可以完成比较大小操作),Comparator接口的实现是在类的外部(可以理解为一个是自已完成比较,一个是外部程序实现比较)
- 实现Comparable接口要重写compareTo方法, 在compareTo方法里面实现比较
Arrays.sort 底层的排序算法是什么?
元素个数 < 47使用插入排序47 <= 元素个数 < 286或者286 <= 元素个数 且数组不具有结构(增减趋势)使用快排286 <= 元素个数 且数组具有结构(增减趋势)使用归并排序
Arrays.sort()方法中有双轴快排为什么还要有归并排序
- 首先当排序数量大于286且连续性好的情况下才用归并排序,连续性不好用双轴快排
- 如果连续性好的情况下用快排,时间复杂度会很高到 $o(n^2)$
Reference: